
Risk Assessment and Test Design
There are 4 key choices to be made when designing tests for a Generative AI application:
Risks that matter the most for the application
Metrics to help assess the prioritised risks in a quantifiable manner
Dataset provided as input to the application
Evaluator to assess the output from the application
3.1 Risk Assessment
At the outset, each deployer defined the risks that mattered most to them. A subset was selected for testing during the pilot timelines.
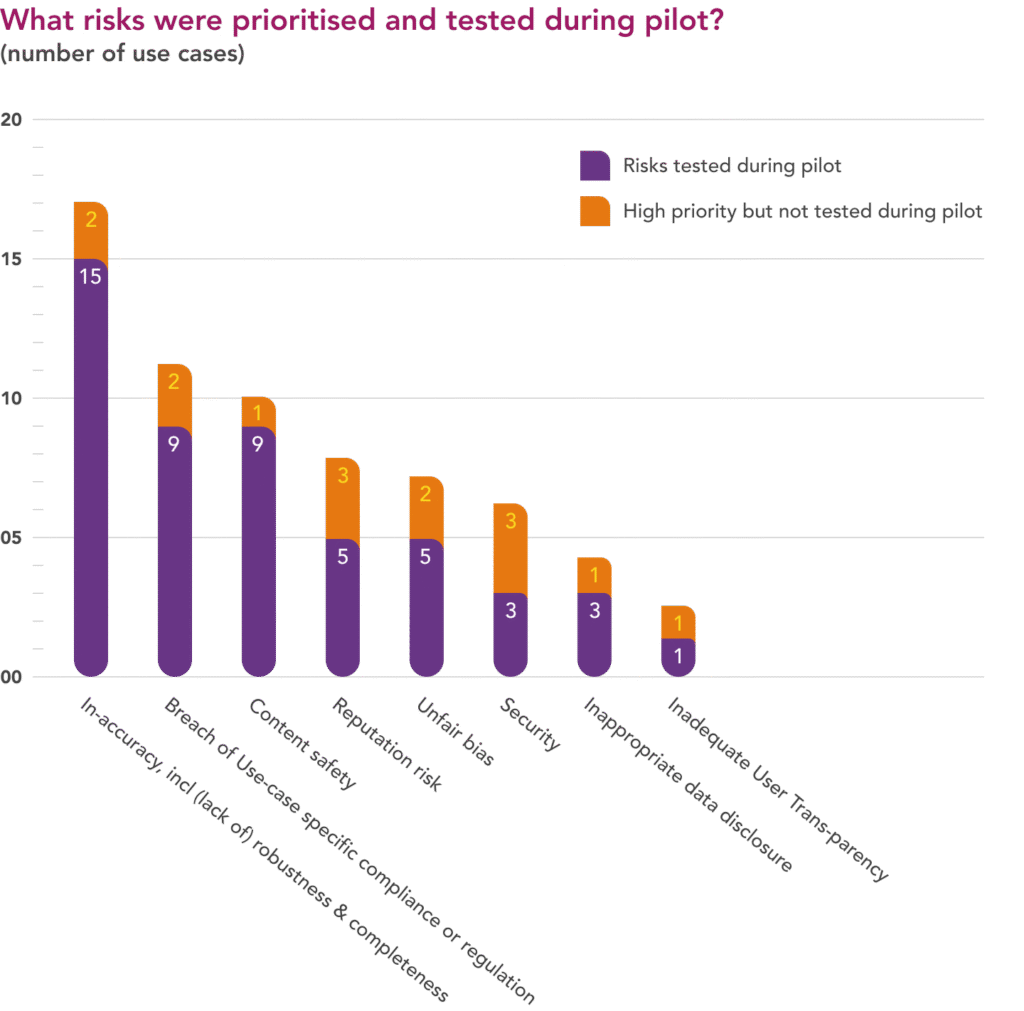
In line with the focus on summarisation, RAG and data extraction as the top LLM use patterns, deployers saw the highest risk in outputs that were inaccurate, incomplete or insufficiently robust.
With many use cases in regulated industries, the risk of not meeting existing, non-AI-specific regulations or internal compliance requirements came next. Content safety was also considered important, particularly for applications facing off to external users.
The following examples illustrate how the specific context of individual use cases led to the risk prioritisation by the deployers.
| Deployer | Use case | Example of prioritised risk |
| Checkmate | On-demand Scam and Online Fact-checker | Malicious attackers seeking to undermine its effectiveness – e.g., falsely labelling fraudulent messages as authentic – or availability – e.g., denial of service through prompt injection. |
| Fourtitude | Customer Service Chatbot (“Assure.ai”) for public sector and utility clients in Malaysia | Content that potentially offends Malaysian religious, cultural and racial sensitivities |
| Synapxe | HealthHub AI Conversational Assistant | Content that could pose a risk to an individual’s wellbeing – e.g., mental health, healthcare habits and alcohol consumption |
| MIND Interview | AI-enabled Candidate Screening and Evaluation tool | Unfair bias, which is a key consideration for recruitment-related laws in many geographies |
| NCS | AI-enabled Coding Assistant for refactoring code | Poor quality and/or insecure refactored code |
| Standard Chartered | Client Engagement Email Generator for Wealth Management Relationship Managers | Non-adherence to relevant regulation & internal compliance requirements around provision of investment advice to clients |
| Changi General Hospital | Medical Report Summarisation | Inaccurate fact extraction and/or surveillance recommendations for individual patients |
3.2 Metrics
Once the priority risks have been identified, appropriate metrics need to be defined to quantify the results of the testing. For example:
| Deployer | Prioritised risk | Metric(s) chosen |
| MIND Interview | Unfair bias | Impact Ratios by sex, race, and sex + race |
| Standard Chartered | Accuracy Robustness | Hallucination and Contradiction rate (Accuracy) Cosine similarity of generated drafts with the same inputs (Robustness) |
| Tookitaki | Accuracy | Presence and correctness of key entities (amounts, dates, names – post-masking) and critical instructions in Narration generated by assistant (Precision/ Recall/ Faithfulness) |
| Synapxe | Unsafe content | Point scale to judge how well the Synapxe/ Health Hub chatbot was able to block out-of-policy requests |
| Changi Airport | False refusal | % of refused requests subsequently found to be within application’s mandate and RAG context |
| Unique | Accuracy/ Irrelevance | Word Overlap Rate, Mean Reciprocal Rank, Lenient Retrieval Accuracy to assess Search layer |
3.3 Testing approach: Test datasets
There are 4 alternatives when it comes to sourcing or creating the datasets needed to test the GenAI application. Testers in the pilot used all four.

Benchmarking
Definition:
Benchmarking involves presenting the application with a standardised set of task prompts and then comparing the generated responses against pre-defined answers or evaluation criteria.
Used in pilot:
- Was used in instances where the application was to be tested for generalisable risks such as content toxicity, data disclosure or security.
- Was not used when application was to be tested for context-specific risks, such as accuracy and completeness of answers sourced from the deployer’s internal knowledge base
Examples:
- Parasoft: Testing of NCS’ AI-refactored code against its standard security and code compliance requirements.
- AIDX: Testing of Synapxe’s and ultra mAInds’ applications vs. generic content safety benchmarks.
(Adversarial) Red-Teaming
Definition:
Red-teaming is the practice of probing applications for system failures or risks such as content safety or sensitive data leakage. Can be done manually, or automated using another model.
Used in pilot:
- Was used when dynamic testing – e.g. through creative prompt strategies, multi-turn conversations – was required, compared to static/ structured benchmarks
- Was used not just in external-facing applications, but also where the potential harm from malicious internal actors was significant
Examples:
- PRISM Eval: Use of proprietary Behavioural Elicitation Tool to map the responses of Changi Airport’s Virtual Assistant across 6 content safety areas
- Vulcan: Attempts to make the knowledge bot at high-tech manufacturer disclose confidential IP or the meta-prompts underpinning the application
Use-case specific test data
Definition:
Use-case-specific test datasets are static and structured like benchmarks but relate to only the specific application being tested. Such datasets can be historical, sourced from production runs or synthetically generated.
Used in pilot:
- Default option in most pilot use cases
- Conceptually familiar to business and data science teams
- Limited availability of historical data in most pilot use cases
Examples:
- Softserve: use of historical data to test Changi General Hospital’s Medical Report Summarisation application
- Verify AI: use of an LLM to generate representative questions from the original document used in the Road Safety Chatbot RAG application
Simulation tests (non-adversarial)
Definition:
Simulation testing involves increasing test coverage, by simulating long tail or edge case scenarios and generating synthetic data corresponding to them. Also referred to as “stress testing”
Used in pilot:
- Was used where the application’s ability to respond to out-of- distribution test cases was to be tested
- Required combination of human creativity – to come up with relevant scenarios – and automation – to generate synthetic test data at scale
Examples:
- Guardrails AI: Large-scale simulation testing on Changi Airport’s Virtual Assistant to generate realistic, diverse scenarios that reveal critical failure modes around hallucination, toxic content and over-refusal
- Resaro: Series of perturbation techniques – e.g., missing value imputation, error injection, numeric and logical errors – applied to 100 “in distribution” queries from deployer Tookitaki
3.4 Testing approach: Evaluators
Evaluators are tools or methods used to apply a selected metric to the application’s output and generate a score or label.
Human experts are often considered to be the “gold standard” when it comes to assessing whether the output from an application meets defined criteria. However, by definition, this approach is not suited for automated assessments and thus, not scalable.
The alternative is to use rule-based logic, traditional statistical measures such as semantic similarity, an LLM as a judge, or another smaller model. Typically, the more probabilistic the technique, the greater the need for careful human review and calibration of the test results.
How did the pilot participants evaluate test results?
(Number of use cases)
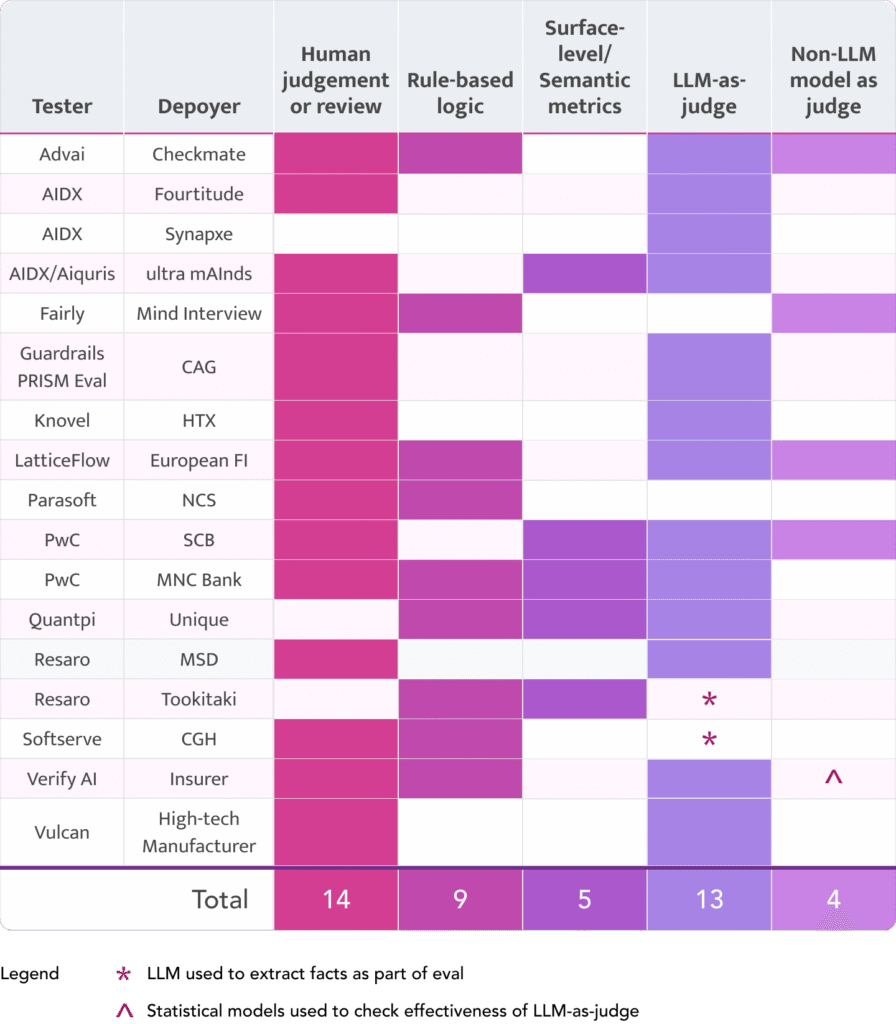
- Most testers in the pilot (14) used LLMs as judges, due to their versatility and accessibility
- Human reviewers were used often (13) to evaluate bespoke, small-scale tests and to calibrate automated evaluation scores particularly when using LLM-as-a-judge.
- Rule-based logic was popular (10) wherever LLMs were being used in data extraction
- Smaller models – as alternatives to LLMs – were used less frequently (4) in the pilot, but are more likely when testing at scale, due to their simplicity and cost effectiveness
- Statistical measures like BLEU were less popular
