


Adversial testing
Synthetic Data for Adversarial Testing

By David Sully,
Co-Founder, Advai
Why do we break things?
If you ask a toddler, it’s probably just for fun. But as we grow up, we break things to understand them better. You can only get so far with theory—eventually, you need to smash something.
Whether it’s particles in an accelerator or a car with crash dummies, breaking things reveals how the universe works or how a seatbelt can save your life. AI is no different – at some point, you need to try and understand what will happen when it experiences things it should not. And for that, you need Adversarial Testing.
Adversarial testing involves feeding in data designed to break your AI model—until it breaks. The ease with which it fails helps you understand its true boundaries: what it handles well, where it struggles, what it detects reliably, and what it cannot be trusted with. Adversarial testing isn’t just a red-teaming trick—it’s the way to truly understand AI systems. If you’re not doing it, you probably don’t know your system as well as you think.
Yes, this is an expert-led craft. But if you’re going solo, here’s a crash course:
Define Your Use Case and Critical Failure Modes
Where failure is unacceptable? Bias, hallucinations, being tricked (e.g. prompt injections), fairness, safety? Prioritise what matters most.
Use Data Mutation Techniques
Modify real data to stretch model limits, for example:
Text: typos, paraphrases, entity swaps, jailbreaks, injections
Images: occlusion, lighting, clutter, adversarial noiseLeverage Generative Models
Prompt LLMs or diffusion models to create hard-edge examples—corner cases, misleading phrasing, traps your model might fall into.
Measure and Benchmark
Numbers mean more in context. Benchmark different models or versions side-by-side to see what truly improves.
Automate It
You’re in AI—automate your adversarial pipeline
Simulation testing
Learning from self-driving cars: Simulation Testing

Safeer Mohiuddin,
Co-founder, Guardrails AI
Visit San Francisco today, and you can summon a Waymo self-driving car – no human driver required. Surprisingly, the fundamental technology enabling these self-driving cars has changed little in the past decade. What’s truly advanced is the painstaking process of identifying and solving the ‘long tail’ of edge cases – those rare but potentially catastrophic scenarios that could lead to accidents.
This journey mirrors the challenges facing GenAI application builders today, where the non-deterministic nature of large language models creates not only safety but reliability concerns. Effective GenAI systems require both rigorous testing to identify edge cases during development and protective guardrails once in production—mirroring the dual approach that ultimately brought self-driving cars from concept to reality.
Catching a 0.01% failure with 99.99% confidence requires testing approximately 10,000 prompts per risk category—making blind brute-force testing untenable.
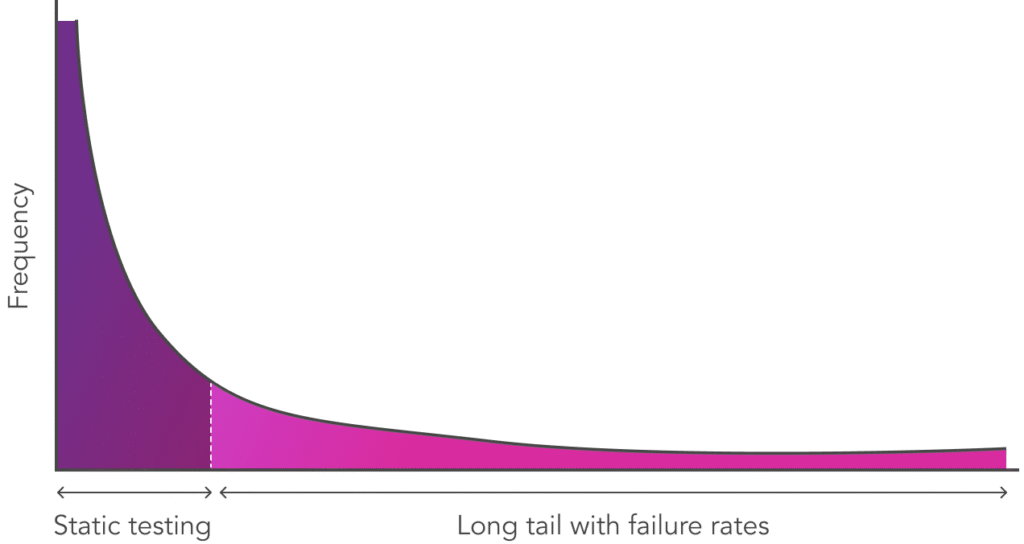
Building on lessons from autonomous vehicles, we’ve identified four complementary testing approaches that together form a comprehensive strategy.
| Technique | Goal | Zones Tested | Metrics |
| Static Dataset | Precision | Known-knowns | Pass-rate threshold (“≥ 95% must pass”) |
| Simulation Testing | Coverage | Known-unknowns, Edge cases | Failure density (“1 critical per 5K runs”) |
| Human Review | Alignment | Subjective failures | Human-quality mean |
| Redteaming | Resilience | Adversarial unknowns | Time-to-bypass |
Simulation testing stands out in this ladder by generating thousands of diverse test cases at scale—uncovering hallucinations, off-topic responses, and policy violations that manual test creation would miss.. By mastering edge case generation, we can build AI systems that handle the unexpected with the same reliability that finally brought self-driving cars safely onto our roads.
LLMs-as-Judges
LLM-as-a-judge

Leigh Bates,
Partner PwC UK and Global Risk AI Leader
Powerful advantages in speed, scalability, and consistency, but effectiveness depends on thoughtful design, human oversight, and awareness of limitations
Testing tools built on Large Language Models (LLMs) rely on testing and evaluating many prompt-answer pairs over different risk metrics, such as accuracy, lack of hallucinations, coverage, robustness as well as adherence to any specific requirements (e.g. that an external chatbot shouldn’t make commercial commitments).
Such evaluation can be done using Natural Language Processing (NLP) and statistical techniques as well as human SME evaluation, but both pose challenges:
- NLP and statistical approaches can act as a good baseline for assessing the accuracy of LLMs outputs, but they are not flexible and sometimes fail to capture linguistic nuance
- Human SME evaluations are more reliable and can add an important layer of testing for higher risk use cases. However, obtaining statistically meaningful results through human assessment is nearly impossible and impractical.
To address this, PwC has developed AI testing toolkits based on an “LLM-as-a-Judge” approach. LaJ typically involve prompting the judge LLM to evaluate whether a given prompt–response pair from an LLM-based system meets a specific requirement. The LaJ prompt can be supplemented with ground truth or examples of appropriate outputs.
Using LaJ in assessing LLM systems has benefits, including:
- Better ability to approximate human-like judgment vs. NLP methods, in areas where evaluation is qualitative (e.g., tone appropriateness, helpfulness).
- Speed & cost effectiveness of executing tests at scale, relative to human review
- Not susceptible to fatigue, unlike human reviewers, which could lead to fairer and more standardised evaluations across large datasets.
- The potential to use the same LaJ beyond initial testing – in ongoing monitoring. This can create dynamic performance metrics and associated alerts
- The potential to extend to Agentic AI system evaluation, where multiple LLMs with different instructions interact with each other without human intermediaries
Of course, there are challenges to consider when using LaJ for evaluation testing:
- Heavy reliance on effectiveness of the prompt used to guide it. The more complex the assessment, the more elaborate and specific the prompt will need to be; this is hard to determine without an element of trial and error.
- Lack of transparency in LaJ reasoning, making it difficult to audit decisions or understand failure modes, especially when evaluating edge cases/ novel inputs
- Risk of biased assessments if using the same underlying model or family of models in the LaJ and the LLM application being tested (however, not observed in the LLM system assessments we have done so far)
There may be the temptation to rely solely on LaJ outputs due to their convenience. However, it is important to reinforce that these tools should supplement (not replace) expert human judgment, especially in high-stakes evaluations. Having human experts test a smaller sample of scenarios to ensure the LaJ is working as intended, and interpret some of the LaJ outcomes, is crucial.
Role of Human Expert
LLMs can’t read your mind

Shahul E.S,
Co-Founder, ragas
Why human review and annotation matters in evaluations
Many teams underestimate the criticality of human review when setting up automated evaluations. If your goal is to align your AI system with human expectations, you must first define those expectations clearly. Here’s how you can go about it
01
Define what to measure
Ask: What matters in a good response for your use case? Pick 1–3 dimensions per input–response pair. For example, response correctness and citation accuracy for a RAG system, or syntactic correctness, runtime success and code style for a coding agent.
02
Choose metric type
For each dimension, choose a metric that’s both easy to apply and actionable:
- Binary (pass/fail): Use when there’s a clear boundary between acceptable and unacceptable. Example: Did the agent complete the task? Yes or no.
- Numerical (e.g. 0-1): Use when partial credit makes sense and you can clearly define what scores mean. Example: Citation accuracy of 0.5 = half the citations were incorrect.
- Ranking: Use when outputs are subjective and comparisons are easier than absolute judgments. Example: Summary A is better than Summary B.
03
Review and evaluate the automated evaluator
Once you are satisfied that you have defined what you really want to measure and have found a way to automate the calculation of your preferred metric, the next step is to assess how well the automated evaluator is performing, and whether it is aligned to the human subject matter expert’s views. However, in doing so, it is essential to collect justification alongside it. “Fail” without a reason isn’t helpful. On the other hand, a good justification can act as crucial training input for your LLM-as-judge.
Finally, do not under-estimate the power of a good user interface in making human reviews/ annotations painless. Looking at data can be tedious, but a user-friendly “data viewer” can make it less so. Your data viewer should ideally be:
- Tailored to your use case (RAG, summarization, agents, etc.);
- Fast to label;
- Structured enough to store data and feedback consistently.
