
Lessons learnt
Observing the 17 sets of pilot participants as they went about testing the applications – prioritising risks, defining test metrics, coming up with suitable test datasets and evaluators, and executing the tests in constrained conditions – provided invaluable insights. These have been distilled into 4 practical recommendations.




The role of the human expert is still paramount for effective testing!
5.1 Test what matters
Running some tests and computing some numbers, that is the easy part. But knowing what tests to execute and how to interpret the results, that was the hard part.
Martin Saerbeck – Aiquris
In theory, it should be easy to determine “what to test” in a GenAI application. In practice, three factors made it challenging for the pilot participants.
Broad risk surface
- Extensive, rapidly evolving and often daunting list of risks associated with GenAI technologies in public domain.
- Difficult for lay persons, or even technical/ functional experts, to discern what might apply to a specific situation
Unfamiliar territory for automation efforts
- GenAI use cases often in areas that have traditionally not seen attempts at automation
- As a result, there are fewer precedents to call upon, when defining good and bad outcomes
Non-quantitative nature of outputs
- Specifying “what good looks like” is subjective and much harder, when the output is in free text – e.g., Is this summary of the source text good enough?
- In comparison, most traditional models have numeric or categorical outputs, and suited for clear-cut assessments
The pilot provided useful tips around the most effective ways of addressing these challenges.
01
To narrow down the risk surface, two approaches have been useful
- Structured down-selection: Start with a comprehensive GenAI risk assessment framework – which are often mapped to relevant regulation/guidelines – and use a structured process to rate the relative importance of each risk for the specific use cases.
Examples:
Include Aiquris-ultra mAInds, PwC – Standard Chartered and NCS – Parasoft.
- Bottom-up approach: Start with the perspective of what really matters to the deployer and impacted stakeholders – without referring to regulatory or compliance frameworks in the first instance.
Examples:
Include AIDX – Fourtitude and Guardrails/ PRISM Eval – Changi Airport (incidentally, both public-facing customer chatbots).
Both options can work, sometimes even in conjunction. The former provides more comfort when regulatory compliance is a key consideration for testing. The latter is often faster and more pragmatic, but could require follow-up to justify decisions.
02
To overcome the lack of precedents to determine good and bad outcomes
- Engage early and extensively with Subject Matter Experts (SMEs) – e.g., with a designated medical practitioner at Changi General Hospital
- Observe outcomes from historical or live production experience where possible – e.g., assessing where the end-user or human in the loop is ignoring/ over-ruling the automated output
- Conduct simulation testing to identify potential failure points in edge cases – e.g., at Changi Airport
- Leverage the experience of specialist testers who have built targeted benchmarks and red-teaming techniques for similar risks
03
Finally, finding quantitative metrics to assess the qualitative outputs is the area that has seen significant practitioner activity already. Tap on the experience of specialist testers and major open source LLM app eval projects.
Make sure that the SME is engaged to shape, review and approve the definition and specific implementation of metrics. For example:
- When using a standard “faithfulness” metric to assess LLM application output vs. the context provided to it. However, it is important to know whether the metric is measuring the extent to which the output (a) can be backed up by the context, or (b) is not contradicted by the context. Needless to say, these metrics measure very different things!
- When using a standard “summarisation quality” metric, the prompt used to assess the completeness of the summary may be equally weighted to all the key claims in the source context. However, in specific situations, getting a particular piece of information – say, the number of polyps in a colonoscopy report – might be a “deal-breaker”, invalidating the summarisation score
5.2 Don’t expect test data to be fit for purpose
Test data is very hard to get in a highly regulated industry like Financial Services
Sina Wulfmeyer – Unique AG
13 out of the 17 pilot participants identified “finding the right test data” as a major challenge during testing. Expect this challenge to exist by default in almost every GenAI testing situation. Budget design and engineering effort, and SME engagement, to address it.
Some potential options to consider are:
- Historical data: At Changi Hospital, historical records were available for individual patients. However, a degree of fresh annotation was needed to make that data suitable for automated testing. Anonymisation efforts may also be needed sometimes, depending on how the historical records were stored.
- Live production data: Not an option during the pilot but can be a relevant option after an application has been live for some time. However, not all applications retain sufficiently granular traces from the application’s responses in the production environment. Additional steps around data anonymisation may also be needed
- Adversarial red teaming: At Changi Airport, PRISM Eval helped create thousands of adversarial attempts by applying their Behaviour Elicitation Tool to the multi-turn chatbot. At Fourtitude, AIDX used seed prompts to create adversarial attacks specific to the Malaysian religious, racial and cultural context.
- Simulation testing: At Changi Airport, Guardrails AI created a series of target user personas with inputs from business, and then used a mix of human creativity and LLM-based automation to generate large volumes of prompts that could test the chatbot’s likely responses in edge-case scenarios.
These guest blogs from Guardrails AI and Advai provide practical guidance on red teaming and simulation testing respectively


5.3 Look under the hood
A key difference between testing an LLM and a GenAI application that uses it is the possibility, and sometimes necessity, of testing inside the application pipeline.
For example, consider this grossly simplified representation of a hospital’s application to summarise medical reports, and recommend personalised surveillance protocols based on established industry guidelines.
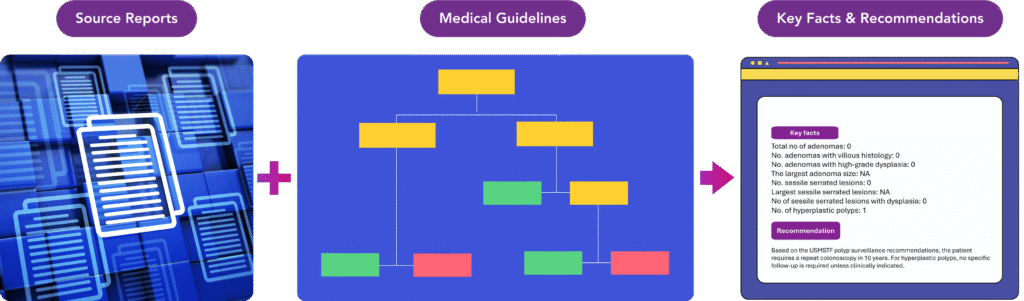
The default approach to testing would be to look at the final output, and assess whether the personalised recommendation for the patient, as well as the key facts extracted from the source medical reports, were in line with the “ground truth” set by a human SME. An LLM-based summarisation quality score could be used as the comparison metric.
At Changi General Hospital, this was the starting point. As part of the pilot exercise, tester Softserve introduced two additional tests:
- Compare the key facts extracted by the LLM from the source reports with the ground truth version of the key facts
- Compare the recommendation implied by the key facts from #1 through the deterministic “decision tree” underpinning the standard industry guideline
Such an approach can provide several advantages, though it also entails greater effort and is therefore more suited to high-stakes use cases.
- Redundancy in automated evaluations: additional triangulation points for the final output’s summarisation score.
- Assistance in debugging application: additional traceability can help understand root causes for poor summarisation scores in the final output
- Lower dependence on LLMs as judges: Python scripts rather than LLM-based evaluators used for the incremental two tests.
Another example of the advantages of looking “under the hood” comes from the red teaming exercise conducted by Advai on Checkmate’s multi-step agentic flow. By knowing the hand-offs at each step of the agentic workflow, the Advai team were able to refine their adversarial attacks on the application.
What about Agentic AI?
“Looking under the hood” becomes even more important in the context of real-life applications that use agentic workflows. The example below – from outside the pilot – illustrates a basic agentic workflow to conduct fraud investigations, and the granular testing to which it may lend itself.

5.4 Use LLMs as judges, but with skill and caution

Using LLMs as judges is unavoidable for evaluation of GenAI applications in many instances. For example, when assessing a response from a GenAI application on:
- Nuanced considerations such as consistency with company values
- Appropriateness from a racial or religious sensitivity perspective
- Quality of language translation
- Completeness and accuracy of summarisation
In all these examples, it is possible to use a human SME as an alternative. However, this can be costly and difficult to scale even in pre-production testing. It becomes practically impossible in real-time production environments, unless a decision is taken to permanently keep a human-in-the-loop.
Of course, using an LLM as judge carries several risks as well. Mitigating them requires:
- Skilful and careful prompting when constructing the evaluator
- Extensive human calibration
- Ongoing monitoring to ensure that there are no “silent failures”
- Concerted effort to explain how they work, and what are their limitations, to the non-technical stakeholders accountable for the final application
- Non-trivial spending on LLM credits or compute capacity
This guest blog from PwC provides a broader introduction to the pros and cons of using LLMs as judges.

Unsurprisingly, almost every tester in the pilot has used LLMs as judges as part of their evaluator design. The detailed case studies document the steps they have taken to improve reliability of such automated evaluators. Most of them used extensive human calibration to mitigate risks, with some using statistical approaches to ensure evaluation robustness.
Beyond the pilot stage, it is expected that several of them may find cheaper, simpler and more transparent alternatives such as smaller language models, rule-based logic or some combination to replace or complement LLM-based evaluators.
5.5 Keep your human SMEs close!
At every stage of the technical testing lifecycle, human SMEs have a critical role to play.
- Narrowing down the risks that genuinely matter in a specific use case
- Helping choose or refine the metrics that can best reflect those risks
- Annotating test data sets, or creating “seed” scenarios that form the basis for synthetic test data generation
- Reviewing/ refining/ validating automated evaluators
- Interpreting test results and deciding on corrective action if any
There is widespread recognition of the theory of involving SMEs from an early stage. Unfortunately, there is inadequate appreciation of the scale of the demands to be placed on the human experts along the way. Additionally, non-technical users often lack user-friendly tools to engage throughout this process.
This guest blog from Ragas provides a practical perspective on how to engage human SMEs in a specific step – that of annotating/ calibrating automated evaluators.

